Spatially Varying Coefficient Models with Spike-and-Slab Group Lasso
2026 Symposium on Data Science and Statistics, Milwaukee, WI USA
2026-04-29
Why Spatially Varying Coefficients (SVC) Models?
- A single global coefficient may mask or distort spatially heterogeneous relationships.
- SVC models let regression effects change with location: \beta_j(s), not a single \beta_j (Gelfand et al. 2003; A. Stewart Fotheringham, Brunsdon, and Charlton 2002).
Published SVC applications show this need in geostatistics.
Air pollution (Hamm et al. 2015)
Forestry (Babcock et al. 2015)
Hydrology (Roksvåg, Steinsland, and Engeland 2022)
Why Selection Matters in SVC Models
Statistical question: which predictors truly need a spatially varying coefficient surface?
- Not every predictor needs a full spatial coefficient surface.
Example. In a county-level diabetes analysis, population density was significant in the model but locally positive in only 0.7% of counties (Hipp and Chalise 2015).
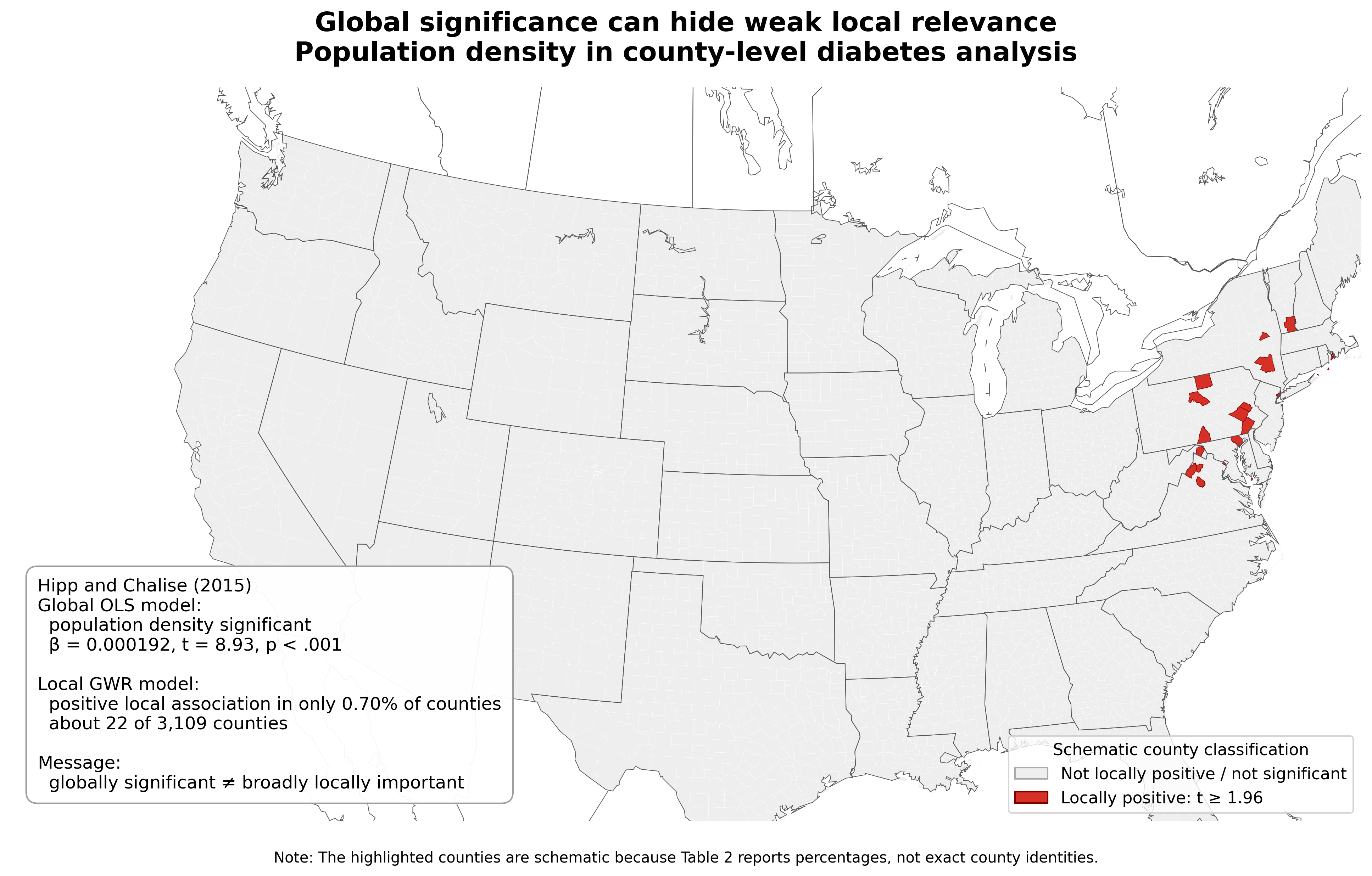
Why Selection Matters in SVC Models
If \beta_j(s) = 0 for all s but x_j is included, the model tries to estimate a coefficient surface that does not truly exist or have any scientific meaning:
-
Estimation (Hastie, Tibshirani, and Friedman (2009); Sestelo et al. (2016))
- Fit random noise instead of real signal
- Spatial smoothing can turn noise into a fake-looking spatial pattern
-
Prediction (Hastie, Tibshirani, and Friedman (2009); Ishwaran and Rao (2005))
- Reduce out-of-sample predictive accuracy
Why Selection Matters in SVC Models
If \beta_j(s) = 0 for all s but x_j is included, the model tries to estimate a coefficient surface that does not truly exist or have any scientific meaning:
-
Interpretation (Gelfand et al. (2003); Greve and Fischl (2018); Brodoehl et al. (2020))
- Misread as scientific evidence
- Suggest that predictor j matters in some locations when it does not
-
Computational
- More parameters must be estimated
- Slower MCMC and longer computation
SSGL-SVC: Basis Representation and Low-Rank Design
Traditional SVC
A separate coefficient at every location for every predictor
Gaussian process dimension grows like O(pn^3)
![]()
SSGL-SVC: Basis Representation and Low-Rank Design
- Approximate each coefficient surface with H basis functions, where H \ll n with complexity O(p(nH^2 + H^3))
Dimension changes from pn location-level coefficients to pH grouped basis coefficients
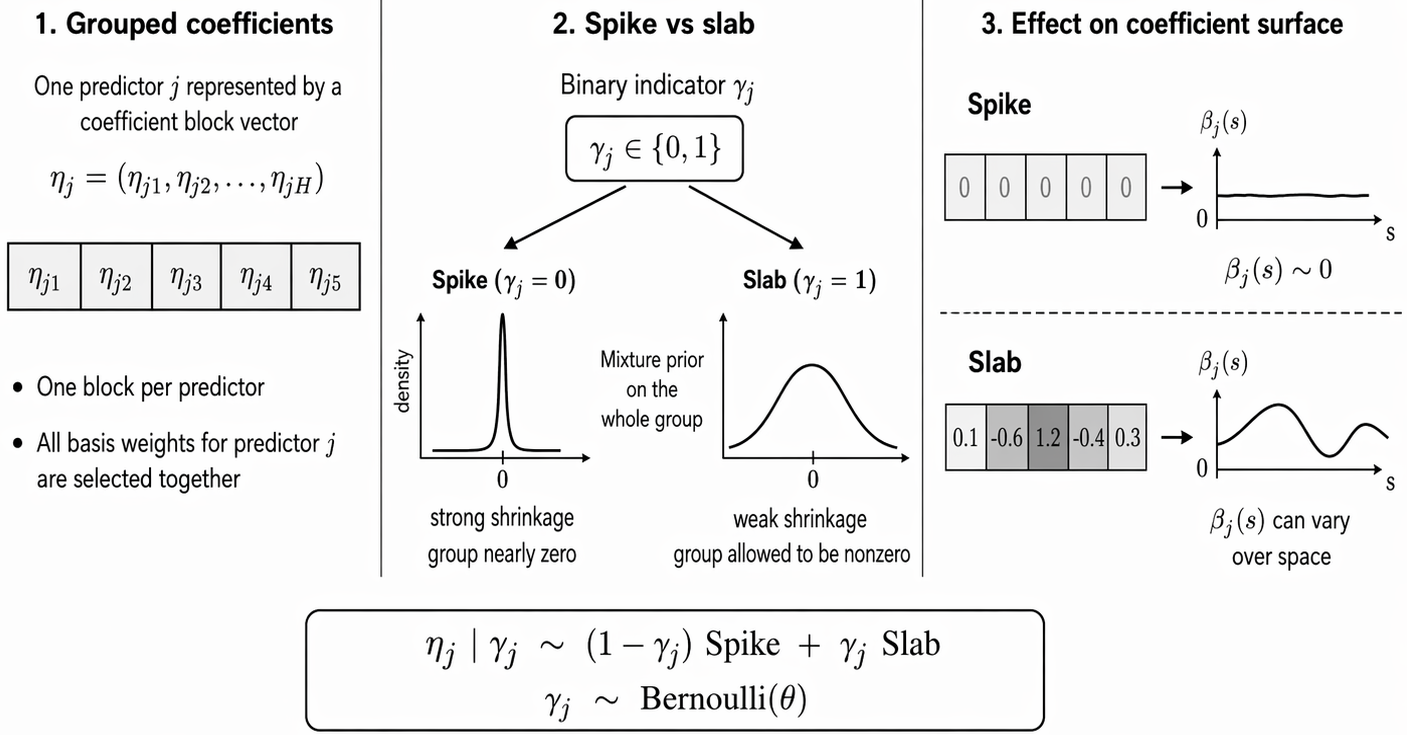
SSGL-SVC: Spike-and-Slab Group Lasso Prior
Basis expansion improves scalability, predictor selection is done via SSGL prior.
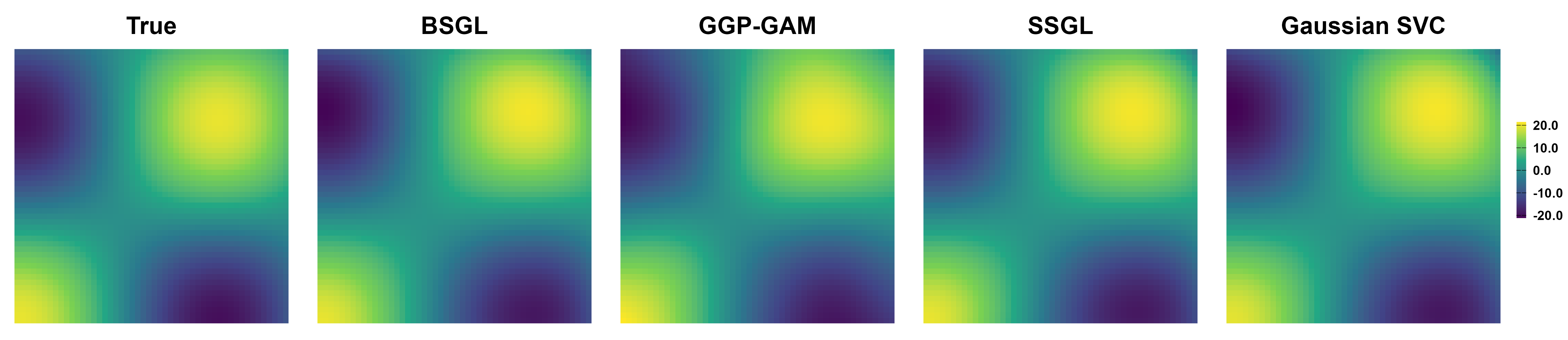
Simulation Results: Surface Recovery
All competing methods well recover the main spatial patterns of active predictors with large signals
Simulation Results: Variable Selection
SSGL-SVC separates signal predictors from noise predictors more sharply than BSGL-SVC and Gaussian-SVC.
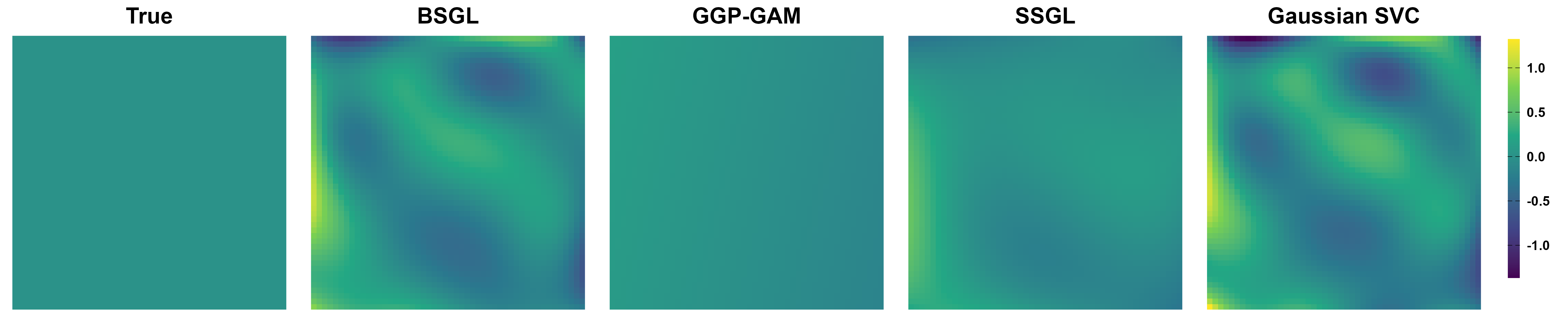
- GGP-GAM seems to work well, but . . .
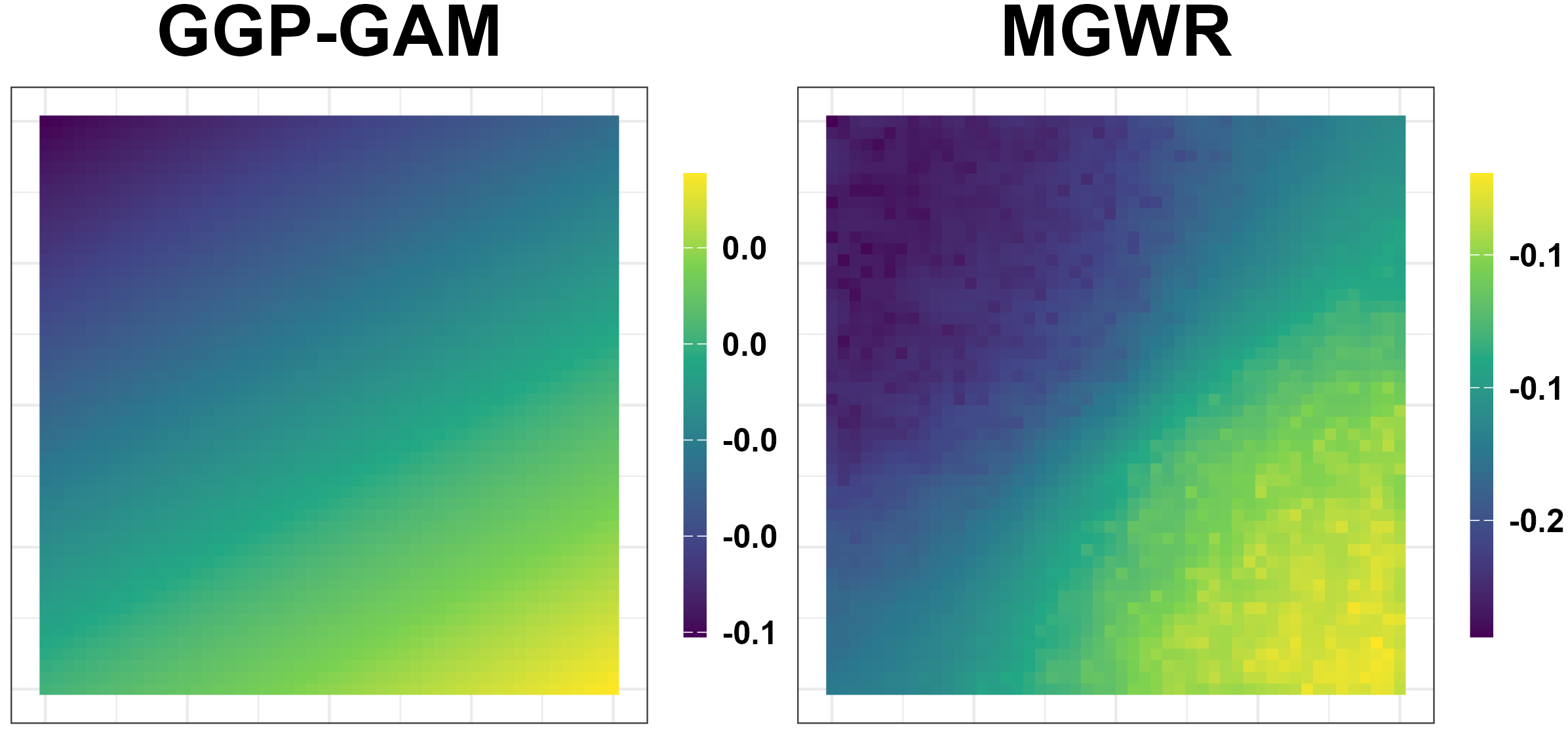
Simulation Results: Unreliable Spatial Patterns
- GGP-GAM and MGWR produce spurious spatial patterns.
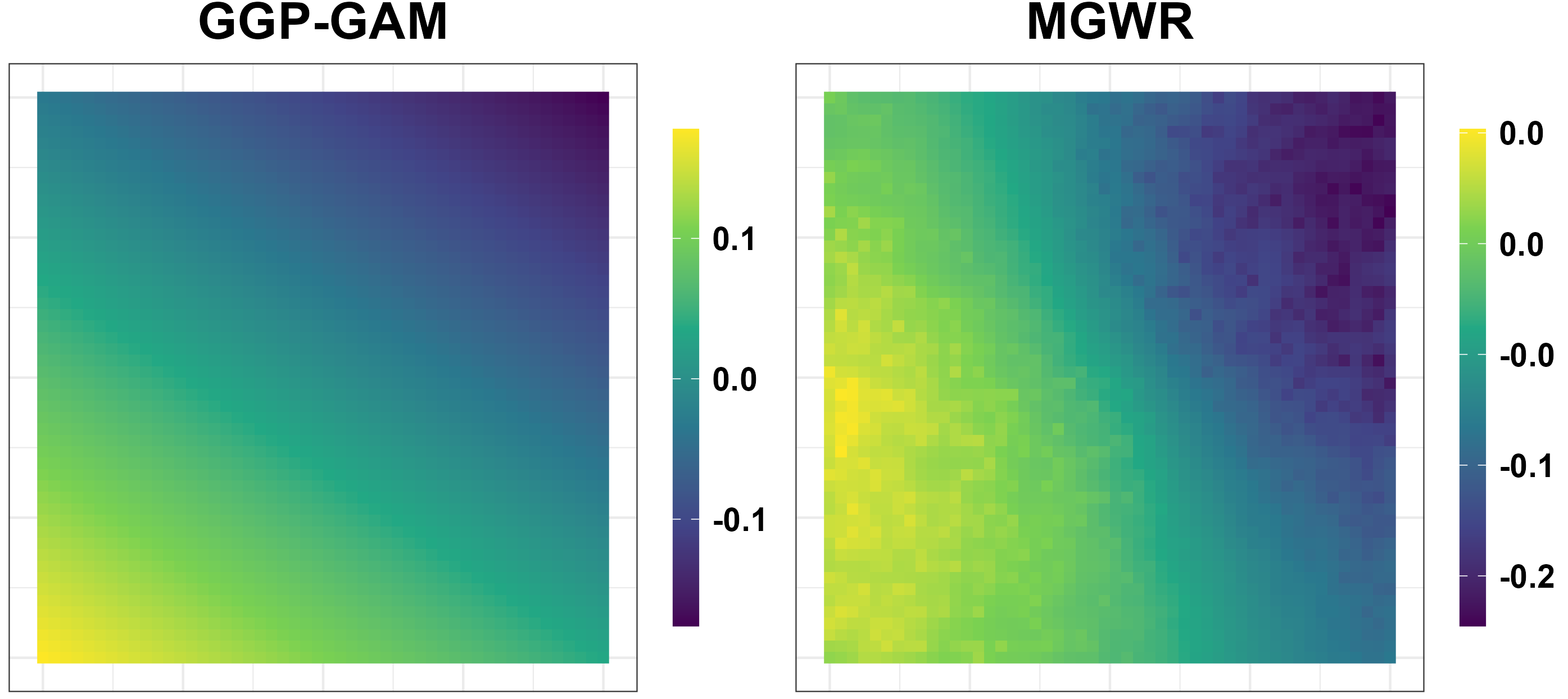
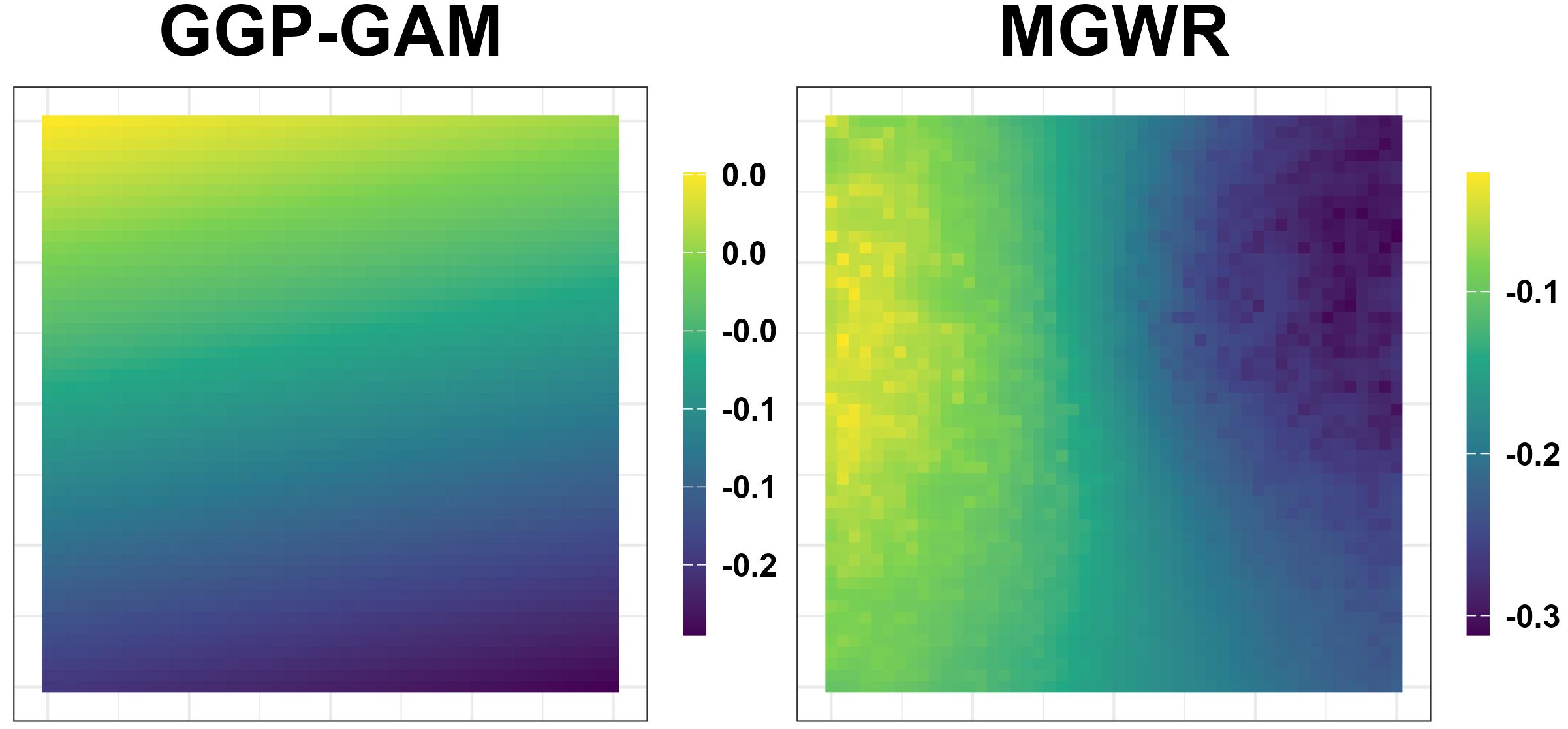
Real Data Application - MODIS
MODIS (Moderate Resolution Imaging Spectroradiometer) by NASA on Western US.
Remote sensing instruments on NASA’s Terra and Aqua satellites.

Real Data Application - Data Summary
Response: Enhanced Vegetation Index (EVI) measuring vegetation greenness (Huete et al. 2002)
-
10 predictors:
- Spectral Reflectance: Red, NIR, Blue, MIR
- Ecosystem: GPP (amount of carbon through photosynthesis), LE (heat flux)
- Satellite Observation Geometry: View/Sun zenith angle, Azimuth angle
- Land Surface: LC Type4
Which predictors have spatially varying associations with EVI?
MODIS: Coefficient Surface and Selection
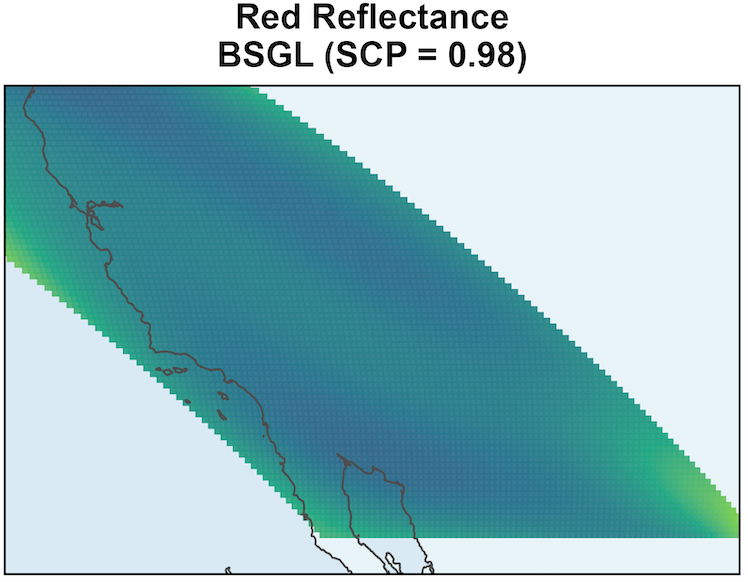
SSGL-SVC leads to larger coefficient magnitudes for variables having effects on EVI, for example, Red Reflectance.
Chlorophyll absorbs red light.
\text{PIP} \approx 1 shows Red Reflectance is associated with EVI, and it has a non-negligible coefficient surface.
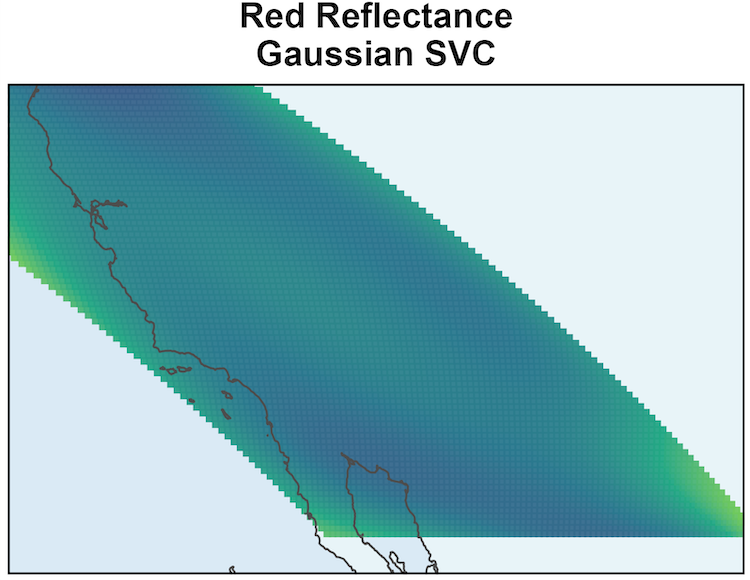
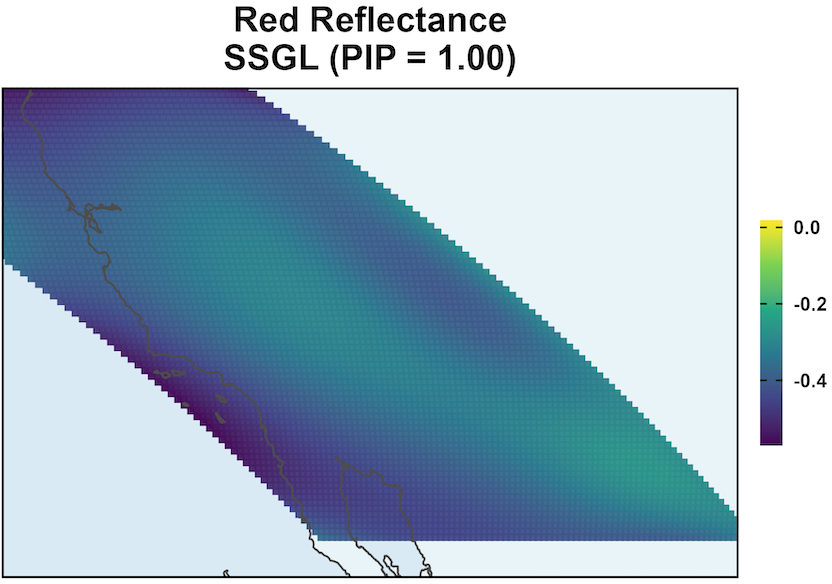
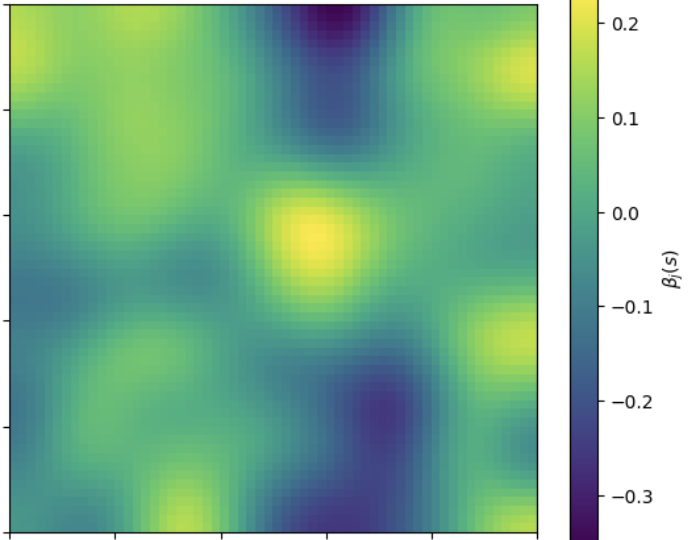
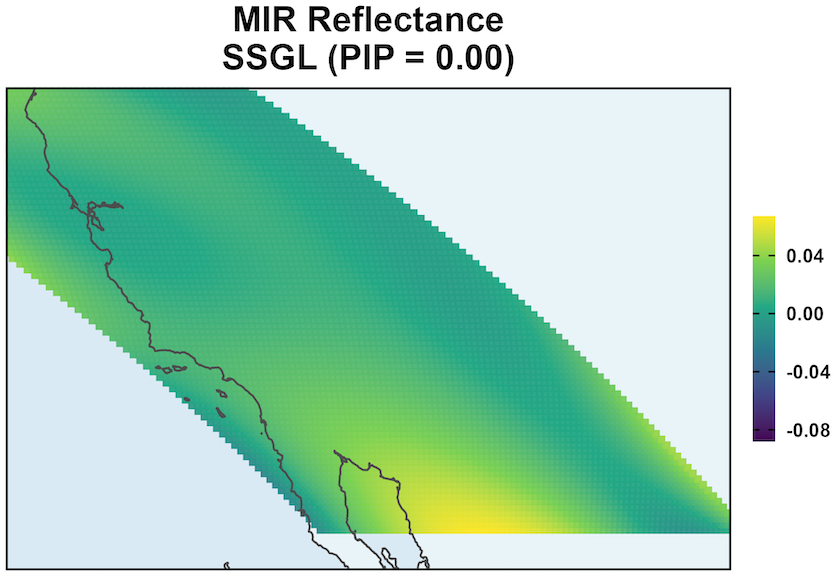
MODIS: Coefficient Surface and Selection
SSGL-SVC shrinks coefficients more toward to 0 when the effect is negligible.
Given all other variables, MIR Reflectance’s effect is negligible with \text{PIP} \approx 0.
Remaining variation in \beta_{MIR}(s) is due to residual posterior uncertainty.
The surface should not be interpreted as meaningful spatial signal.
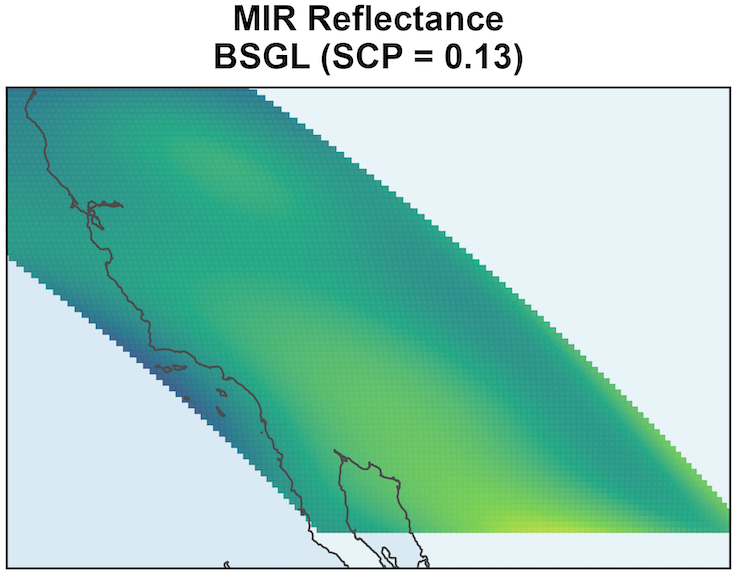
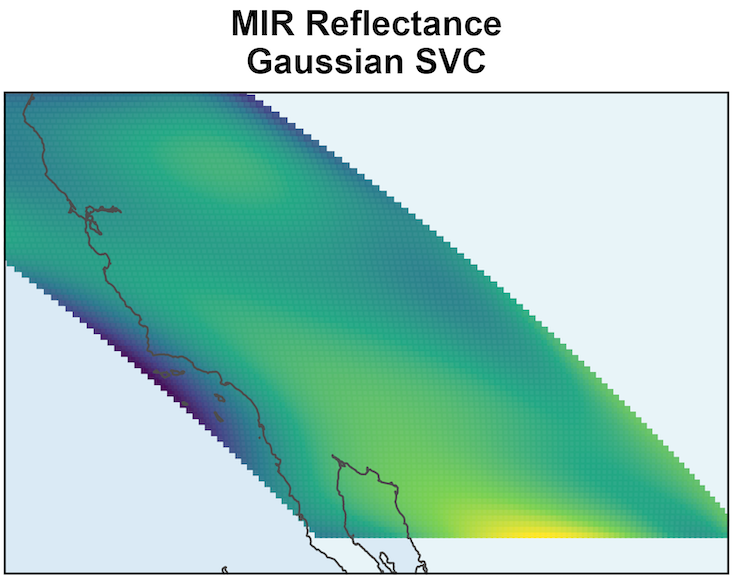
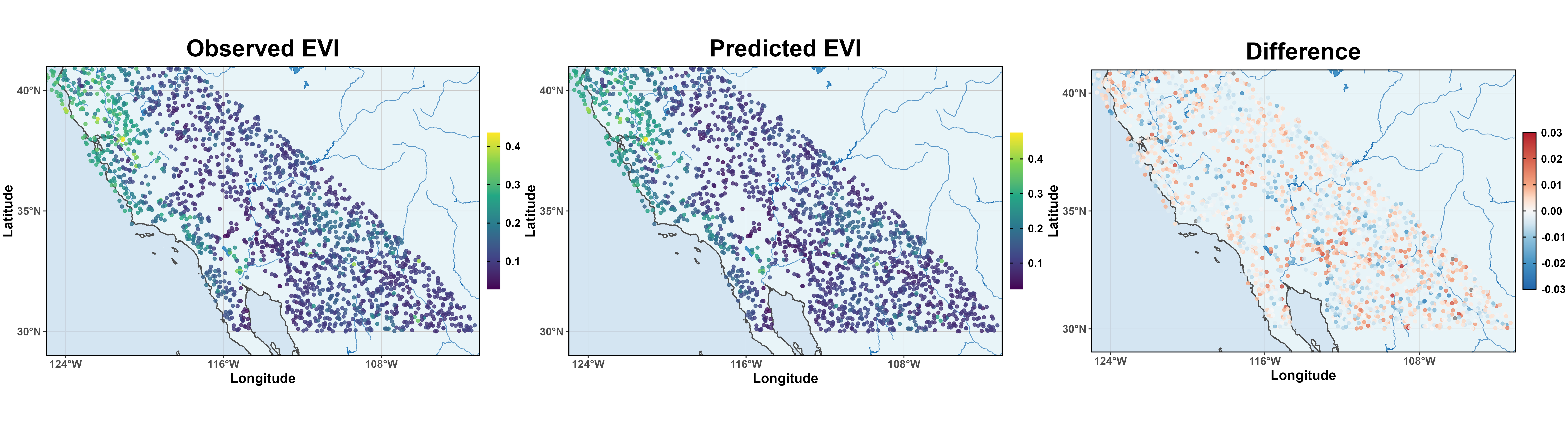
MODIS: EVI Prediction
Great MSPE 8.38 \times 10^{-5} and better than BSGL-SVC and Gaussian-SVC.
Moran’s I verified that there is no spatial correlations in posterior residuals.